![]()

Contents
There are times when you’ll want to add person information and/or pictures into KeepnTrack from outside sources such as your central district or facility database; a process called "importing". The Imports interface places everything you need to quickly find, modify, and run an import of patron, item, and transaction command information.
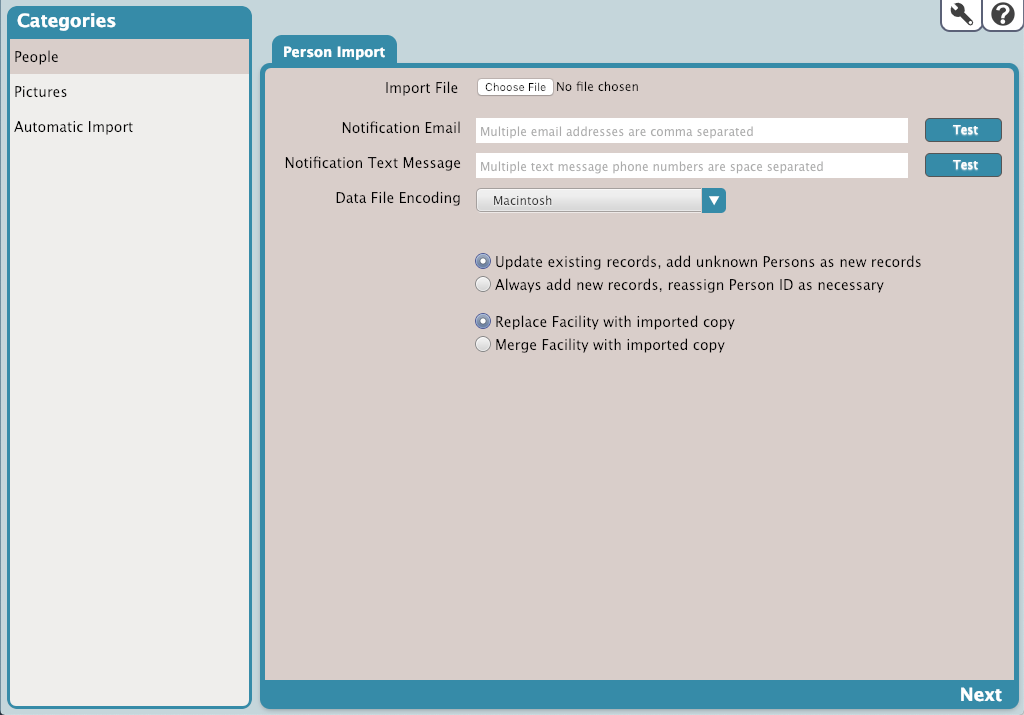
Categories
The first step in performing an import is picking the correct import type. The Categories pane on the left-hand side of the window is where you choose the import whose settings appear in the Import Selection pane on the right.
People
Allows you to upload and integrate person information from simple text documents or data files. Files should be in .txt, .tab, or .csv format.
Pictures
Upload a ZIP file containing person pictures. When importing, KeepnTrack will attempt to match image filenames with Student ID, Person ID, or Staff ID. Image files should be 186 x 240px and must be in the JPEG, GIF, PNG, or BMP format.
Automatic Import
KeepnTrack has the ability to import new (or update existing) Person record information from a record database stored on an FTP server.
Selections
The larger, right-side of the Import interface is dedicated to the selected import type and contains all of the import's configurable settings and options. The information that appears in this pane relates directly to the import type selected from the Categories pane. It contains all of the configurable settings and options essential to how your import is performed. For example, if you select Automatic Import from the Categories pane, the results here will adjust accordingly.
Learn more:
Computerized Records
Before going further, it helps to understand some basic concepts about computerized records. In order to exchange information between different programs (or even between different computer systems), one needs the information in a format that many different programs can understand. The standard, called ASCII[1], is widely used to exchange information between different programs and operating systems. Sometimes an ASCII file is called a text file (.txt) because all it contains is textual information.
ASCII files contain two types of characters: standard visible characters such as numbers and letters of the alphabet, and special control characters used for special purposes to control the display or interpret information in the file. If you have computerized data, you may be familiar with the <tab> and <return> control characters that are used to make text more legible.
When dealing with computerized information systems, you often hear the terms field, record, and file. A field is the smallest unit of information stored. An example of a field is a person's last name. A record is a related group of fields. Many records of the same type saved together are called a file. For example, in a file of names, a record consists of the fields “First Name” and “Last Name”. A more complex file may include records with other fields such as “Phone Number” and “Address”. In other words, records contain fields filled with information, and files contain many records.
Most database, spreadsheet, and word-processing programs support files in a tab-delimited format, which KeepnTrack is capable of importing.
Tab-Delimited Records
A very common method of exchanging record information between programs is the tab-delimited ASCII file. Using tab-delimited import files, you can transfer information about people stored in other computer systems. For example, a school can use this capability to transfer student information from the school administration computer system into KeepnTrack.
In the tab-delimited format, fields are separated by the <tab> control character and the end of the record contains the <return> control character:
Bill <tab> Jones <return>
Smith <tab> John T.<return>
My First Name <tab> My Last Name <return>
The header (first line) of a tab-delimited file allows programs to figure out where the data in the file belongs. In KeepnTrack, we use field codes in the header to identify data:
###*PT01/FieldCode/FieldCode/FieldCode/ <return>
Here is an example of what a KeepnTrack tab-delimited import file looks like, with both the header and tabbed fields:

Each field code in the header represents a People Management field in KeepnTrack (e.g. 1007 is First Name and 1019 is Email Address). Every line below the header represents one person, with their information tabbed and following the order of the field codes.
For a full list of KeepnTrack's field codes, see the Person Field Codes table. Be sure to check out the information on the Facility field, as it's required to import new people and can be a little tricky.